
Por que você ainda usa Virginia como região na AWS?
Ontem (20/10/2025), houve um incidente na AWS que fez com que várias empresas e sistemas ficassem fora do ar. Muitos clientes utilizam a região de Virgínia (us-east-1) como região não produtiva e alguns como produtiva; desses que a utilizam para produção, muitos foram impactados, com a aplicação ficando instável ou até fora do ar.
Não é algo tão incomum de acontecer (é raro, mas acontece). Chuto que, pelo menos uma vez a cada 2 anos, ocorre esse tipo de incidente na AWS, e é sempre um caos, com várias pessoas reclamando e postando na internet que não conseguem usar o produto A ou B.
Conversando sobre esse novo incidente com o Bernardo Costa, comentei que alguns clientes que utilizam a região de Virgínia como ambiente de homologação estavam abrindo tickets relatando a indisponibilidade. Isso o fez levantar a pergunta: "Mas por que estão usando Virgínia?". Na hora, respondi que a região de Virgínia é a que tem a menor latência, e isso poderia ser um motivo para utilizá-la. Mas, discutindo um pouco mais sobre isso, chegamos à conclusão de que, se isso é um motivo, então estamos dizendo que latência é mais importante que disponibilidade. E se isso for verdade, por que não utilizar a região mais próxima do usuário final?
Isso me faz querer discutir um pouco mais sobre a pergunta do título: por que ainda é usada Virgínia como região na AWS? Vou levantar alguns pontos que considero importante ter em mente, tanto com uma visão arquitetural como de negócio, para que cada um possa se questionar se realmente devemos continuar usando essa região como "padrão".
Antes de tudo, estamos no Brasil, e a maioria dos clientes que tive/tenho contato são do Brasil. Então, já quero deixar claro que a outra pergunta levantada ("por que não utilizar a região mais próxima do usuário final?") tem um fator de custo muito forte para justificar rodar o ambiente fora da região de São Paulo (sa-east-1), que é a mais próxima dos clientes no Brasil. O custo, comparado às demais regiões, pode ser o dobro e, comparando com Virgínia, geralmente é o dobro ou acima disso em alguns serviços. Por isso, a discussão vai se concentrar em 2 cenários específicos para diminuir variáveis que podem complicar a resposta da pergunta inicial:
Ambiente produtivo em São Paulo devido à latência ser um requisito não funcional muito importante (um sistema de streaming de áudio ou vídeo, por exemplo) ou para cumprimento de regulamentações, mas com ambiente não produtivo fora de São Paulo.
Ambiente em que o custo é o requisito não funcional mais importante que a latência ou que não precisa cumprir alguma obrigação de execução no Brasil, logo, pode ser executado fora de São Paulo.
Com isso setado, vamos elaborar alguns pontos de reflexão que serão comuns para os 2 cenários.
Latência
Considerando a questão da latência, podemos dizer que é justificável utilizar Virgínia porque a latência dessa região é menor do que a das demais. Mas será que é mesmo? Vamos olhar de fato para isso e fazer uma comparação com as demais regiões. Abaixo está o print do site https://awsspeedtest.com/ que compara a diferença de latência entre as regiões.
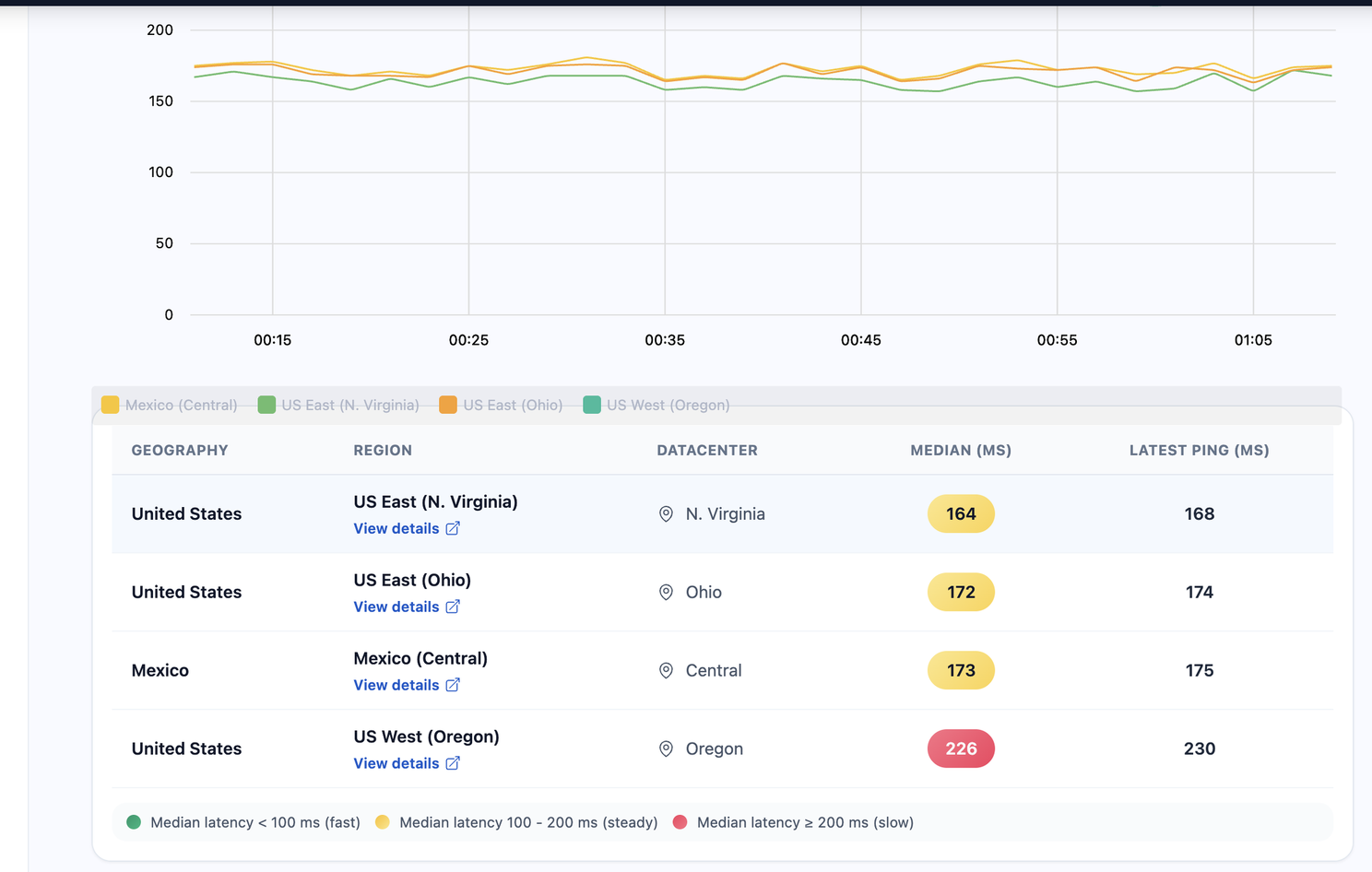
Como podem ver, na média, realmente Virgínia tem uma latência menor comparada com outras regiões. Mas a segunda menor, que é Ohio, tem uma diferença de apenas 8 ms acima, ou seja, apenas 5% mais lento em comparação a Virgínia. Para a maioria das aplicações, isso é uma diferença aceitável e que pode ser mitigada de outras formas, como o uso de cache, por exemplo.
Esse é apenas um recorte e o valor pode variar, mas em todos os testes que fiz a variação será bem próxima dessa faixa de 5% a 10% comparando com Ohio. Então, olhando na perspectiva de latência, vale realmente a pena utilizar Virgínia
Custo
Vamos agora olhar a questão do custo. Vamos escolher Virgínia devido aos custos dos serviços nessa região serem mais baratos do que nas demais, certo? Mas vamos comparar em relação a outras regiões na América.
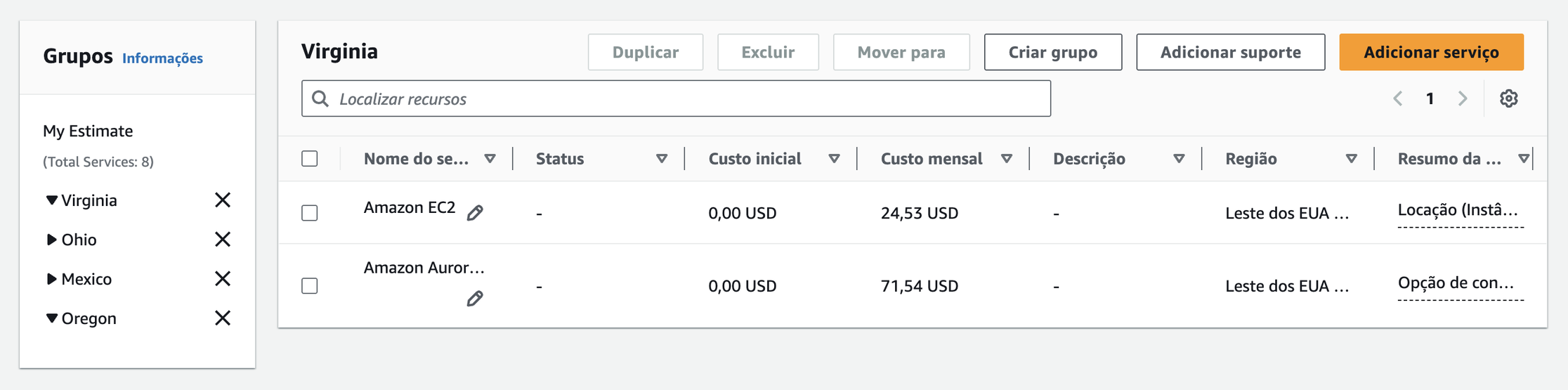
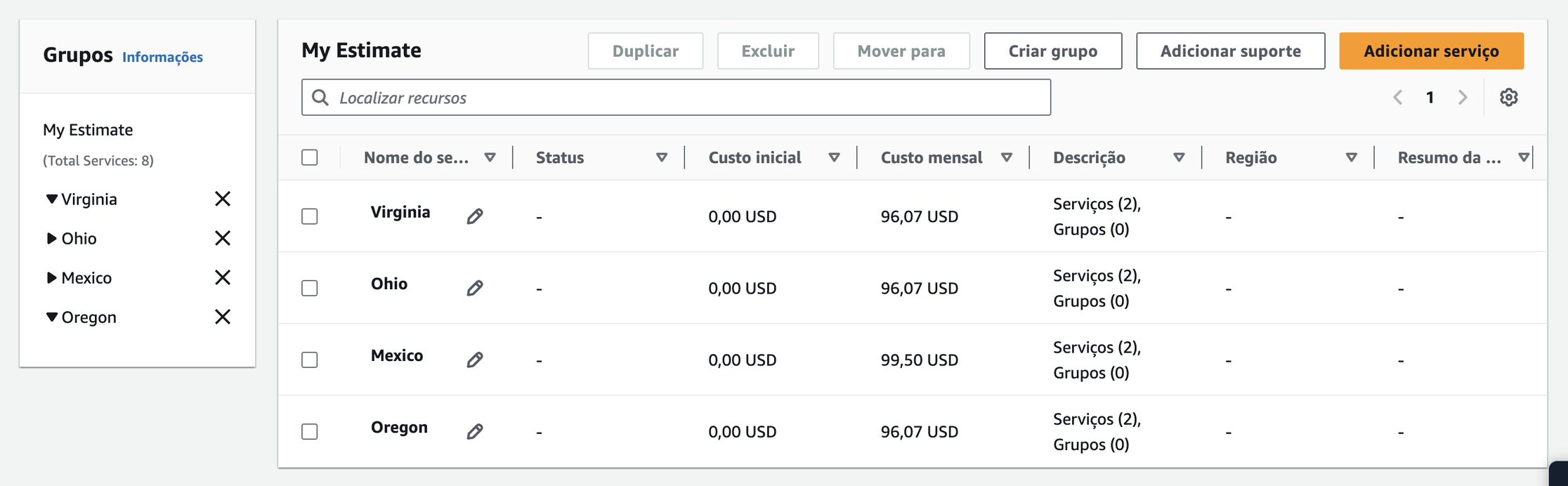
A primeira imagem é a calculadora de uma EC2 e um Aurora PostgreSQL t4g.medium na região de Virgínia, dois serviços básicos que são utilizados em variados tipos de aplicação. Na segunda imagem, temos a mesma calculadora, só que para as regiões de Ohio, Oregon e México. Como podem ver, o preço é igual para os 2 primeiros e o ultimo, sendo maior somente na região do México. Ou seja, o mesmo serviço tem o mesmo custo nas 3 regiões principais dos EUA.
Então, podemos dizer que em outras regiões na América o custo não muda. Por que não utilizar as outras regiões?
Inovação e Novos Serviços
Por último, podemos olhar sob o prisma de novidades e inovação. Por Virgínia ser a primeira região da AWS, é nessa região que são lançados novos serviços e previews de novas funcionalidades. Mas ela é a única? Olhando o histórico dos últimos lançamentos no site da AWS, podemos ver que isso já não é verdade há algum tempo.
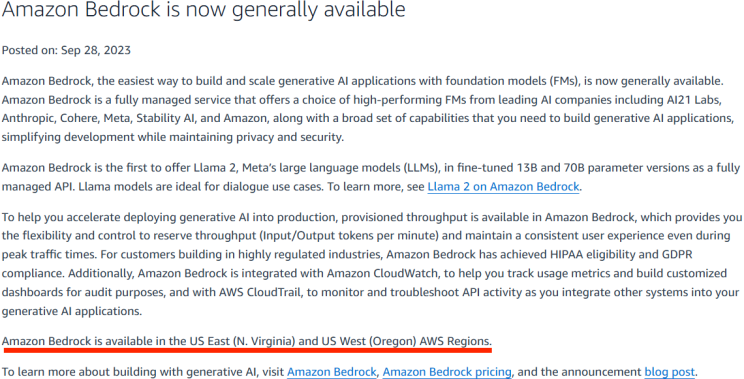

Nas imagens, podemos ver que os novos serviços foram lançados em, pelo menos, mais de uma região além de Virgínia, e em todas elas foi lançado também em Oregon. Nesse caso, não precisamos utilizar Virgínia para ter disponível um novo lançamento na AWS; podemos usar Oregon.
Efeito Manada
Quando a AWS foi criada, a primeira região a ser disponibilizada foi Virgínia, e todos os serviços que foram surgindo eram disponibilizados nessa região. Com o tempo, a AWS foi disponibilizando novas regiões, mas, como Virgínia era a inicial, se tornou a principal de alguns serviços, como o IAM ou o Route53, que, mesmo sendo serviços globais, têm (ou tinham) Virgínia como endpoint principal. Logo, se os principais serviços globais da AWS estão ancorados nessa região, é porque ela é capaz de suportar esses serviços e tem a capacidade de atender a essa demanda. Não à toa, a região da Virgínia é a única a ter 6 zonas de disponibilidade (o mais comum é ter 3 zonas na região).
Além disso, toda conta nova criada na AWS já iniciava, por padrão, na região da Virgínia. Agora, imagine para quem está começando a entender sobre Cloud e AWS e pesquisa sobre o que é uma "região": todo o material de início usa Virgínia como exemplo, todos os novos serviços que são lançados é certo de estarem disponíveis lá, e todo tutorial na internet vai explicar sobre o serviço X sendo criado na região de Virgínia.
Isso fortalece o efeito manada: "Se todos falam e utilizam Virgínia, por que usar uma região diferente?". E isso se torna uma bola de neve: se a pessoa vai para Virgínia porque a maioria está usando, maior é o esforço da AWS para suportar essa região, o que reforça o pensamento de continuar usando Virgínia, pois a AWS sabe que a maioria dos clientes está lá.
Conclusão
Com isso, vamos voltar à questão inicial: por que ainda usar Virgínia? E a resposta é que não temos por que continuar usando. Virgínia foi a primeira região criada pela AWS e, por muito tempo, foi a região mais utilizada por ser a primeira; logo, ela se tornou o padrão. Mas, como podem ver, muitos dos motivos que a tornavam a escolha padrão deixaram de ser vantagem, e temos outras regiões que conseguem nos atender.
Caso não tenham percebido, novas contas AWS já são criadas com o primeiro acesso em Ohio em vez de Virgínia, e até a calculadora da AWS, quando você a utiliza, já está também com a escolha de Ohio como região padrão para os serviços.
Então, aconselho a todos os que utilizam AWS a repensar se realmente escolher Virgínia como padrão é necessário. E não como uma forma de evitar o risco do incidente de ontem, porque esse tipo de incidente pode ocorrer em qualquer região (e isso se mitiga implementando um ambiente de DR, o que é um papo para outro post), mas sim para evitar a escolha que por muito tempo era a mais comum. E se a escolha se torna comum, os problemas também são. E todo mundo gosta de evitar problemas, certo?
Talvez você esteja se perguntando: "E se já estou em Virgínia, será que vale migrar? E nos casos onde Virgínia é meu ambiente produtivo, vale o risco?". Bem, esse papo é mais profundo porque envolve algumas definições que tratamos em projetos de DR que vão além da parte técnica e que, antes de qualquer coisa, precisamos ter o impacto do custo de um tempo de recuperação (RTO) e a quantidade máxima de perda de dados (RPO) que uma empresa pode tolerar após um incidente desse nível. Mas já adianto que se você está querendo migrar só porque agora acha que Virgínia é pior que as demais regiões, ou que multicloud seria a solução para esse tipo de problema, você pode estar só trocando para uma nova manada :)